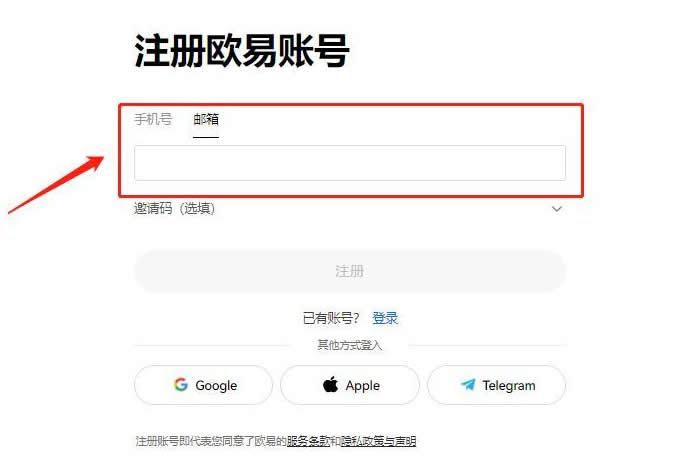
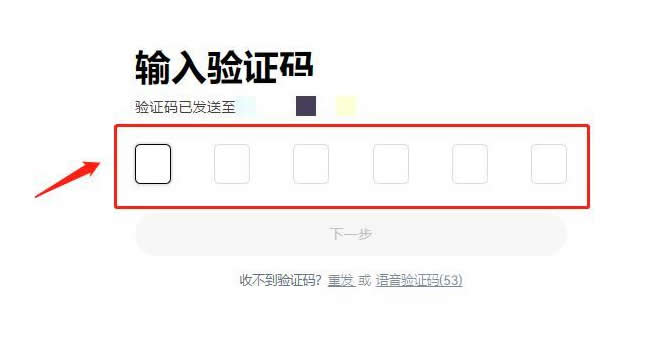
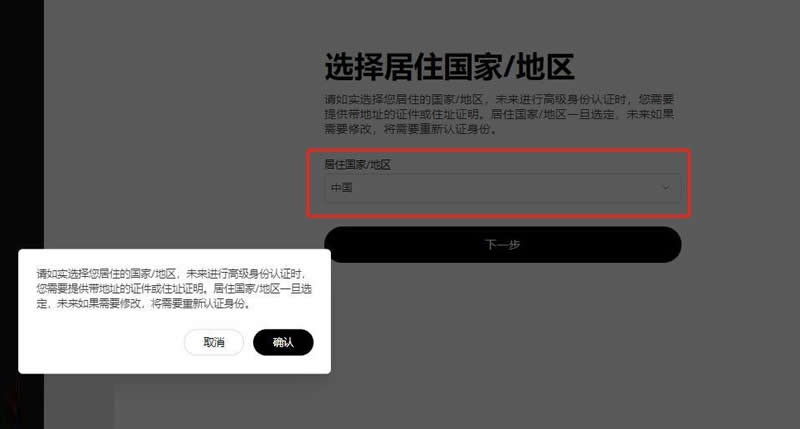
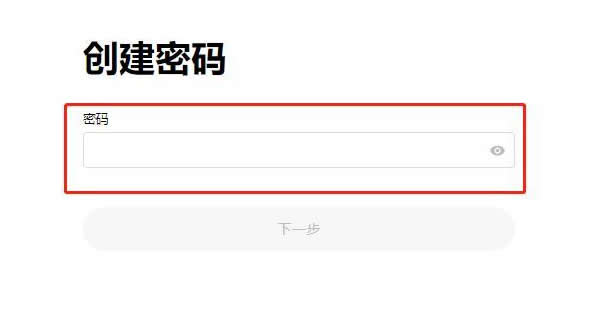
用于搭建Web应用程序免去不同Web应用相同代码部分的重复编写,只需关心Web应用核心的业务逻辑实现
接收并解析HTTP请求,获取具体的请求信息处理本次HTTP请求,即完成本次请求的业务逻辑处理构造并返回处理结果——HTTP响应
如何搭建工程程序
工程的组建工程的配置路由定义视图函数定义如何获取请求数据(操作request对象)
如何构造响应数据(构造response对象)
框架提供的其他功能组件的使用
数据库
模板
admin
重点
MVT流程:掌握M,V,T的每个模块的功能,了解MVT的流程

创建Django项目和应用
django-admin startproject name
python manager.py startapp name
视图和ULR
视图的请求和响应
URL的匹配路径
简介
Django,发音为[`dʒæŋɡəʊ],是用python语言写的开源web开发框架,并遵循MVC设计。劳伦斯出版集团为了开发以新闻内容为主的网站,而开发出来了这个框架,于2005年7月在BSD许可证下发布。这个名称来源于比利时的爵士音乐家DjangoReinhardt,他是一个吉普赛人,主要以演奏吉它为主,还演奏过小提琴等。由于Django在近年来的迅速发展,应用越来越广泛,被著名IT开发杂志SDTimes评选为2013SDTimes100,位列"API、库和框架"分类第6位,被认为是该领域的佼佼者。
Django的主要目的是简便、快速的开发数据库驱动的网站。它强调代码复用,多个组件可以很方便的以"插件"形式服务于整个框架,Django有许多功能强大的第三方插件,你甚至可以很方便的开发出自己的工具包。这使得Django具有很强的可扩展性。它还强调快速开发和DRY(DoNotRepeatYourself)原则。
特点
重量级框架
对比Flask框架,Django原生提供了众多的功能组件,让开发更简便快速。
wps的的官网最新的下载网址怎么找
提供项目工程管理的自动化脚本工具
数据库ORM支持(对象关系映射,英语:Object Relational Mapping)
模板
表单
Admin管理站点
文件管理
认证权限
session机制 缓存
MVT模式
有一种程序设计模式叫MVC,其核心思想是分工、解耦,让不同的代码块之间降低耦合,增强代码的可扩展性和可移植性,实现向后兼容。
MVC的全拼为Model-View-Controller,最早由TrygveReenskaug在1978年提出,是施乐帕罗奥多研究中心(Xerox PARC)在20世纪80年代为程序语言Smalltalk发明的一种软件设计模式,是为了将传统的输入(input)、处理(processing)、输出(output)任务运用到图形化用户交互模型中而设计的。随着标准输入输出设备的出现,开发人员只需要将精力集中在业务逻辑的分析与实现上。后来被推荐为Oracle旗下Sun公司Java EE平台的设计模式,并且受到越来越多的使用ColdFusion和PHP的开发者的欢迎。现在虽然不再使用原来的分工方式,但是这种分工的思想被沿用下来,广泛应用于软件工程中,是一种典型并且应用广泛的软件架构模式。后来,MVC的思想被应用在了Web开发方面,被称为Web MVC框架。
MVC模式说明

M全拼为Model,主要封装对数据库层的访问,对数据库中的数据进行增、删、改、查操作。V全拼为View,用于封装结果,生成页面展示的html内容。C全拼为Controller,用于接收请求,处理业务逻辑,与Model和View交互,返回结果。
Django的MVT

M全拼为Model,与MVC中的M功能相同,负责和数据库交互,进行数据处理。V全拼为View,与MVC中的C功能相同,接收请求,进行业务处理,返回应答。T全拼为Template,与MVC中的V功能相同,负责封装构造要返回的html。
注:差异就在于黑线黑箭头标识出来的部分
为什么要搭建虚拟环境?
举例子:
A项目需要的环境: python2.7 + django1.1B项目需要的环境: python3.7 + django2.2
不装个虚拟环境那就难搞了,python环境中不能同时安装django1.1和django2.2,
所以就需要虚拟环境进行隔离
windows环境:
安装virualenv(这个才是真正才能创建虚拟环境)

新建一个文件夹存放虚拟环境

新建虚拟环境
虚拟环境名称为my_django,自己命名即可
virtualenv my_django

进入并且激活虚拟环境
去到虚拟环境中的Script目录下

执行activate 进行激活虚拟环境

检查虚拟环境 pip list

下面这个是真实环境

这样环境就隔离了。
后面需要安装第三方的包,先进入虚拟环境再安装
退出虚拟环境
直接在虚拟环境中执行deactivate命令,就可以退出虚拟环境了,有的可能需要.bat,有的不需要

安装virtualenvwrapper
上面每次进入virtual我们都需要进入到virtualenv的目录下,一旦virtualenv过多,就麻烦了,我们可以使用Virtualenvwrapper来方便地管理python虚拟环境。

设置WORK_HOME环境变量
给虚拟环境设置一个专门的目录

配置电脑系统环境变量,新建系统变量 -> 变量名:WORKON_HOME ->指定路径:
G:python_webcodeworkpaceenvs

通过设置WORKON_HOME路径,就给我们的python虚拟环境指定了一个存放位置
注意: 环境变量配置好之后,要重开cmd,这样环境变量才生效!!
新建虚拟环境

因为前一步设置了WORK_HOME,所有虚拟环境将安装到:G:python_webcodeworkpaceenvs
退出虚拟环境

进入虚拟环境
workon #列出所以目录下虚拟环境
workon 虚拟环境名称 # 进入虚拟环境

删除虚拟环境

pycharm结合virtualenv虚拟环境使用
只要把pycharm的环境变量选择为虚拟环境的中的python环境即可。

要选择虚拟环境中的 python.exe 文件

Linux环境:
安装虚拟环境的命令 :
安装完虚拟环境后,如果提示找不到mkvirtualenv命令,须配置环境变量:
创建虚拟环境的命令 :
提示:如果不指定python版本,默认安装的是python2的虚拟环境
在python2中,创建虚拟环境
在python3中,创建虚拟环境

提示 :
创建虚拟环境需要联网创建成功后, 会自动工作在这个虚拟环境上工作在虚拟环境上, 提示符最前面会出现 “虚拟环境名称”
如何使用虚拟环境?
查看虚拟环境的命令 :

使用虚拟环境的命令 :

退出虚拟环境的命令 :

删除虚拟环境的命令 :
WPS office电脑版下载的方法怎么找
如何在虚拟环境中安装工具包?
提示 : 工具包安装的位置 :
python2版本下:
python3版本下:
python3版本下安装django-1.11.11的包 :

查看虚拟环境中安装的包 :

步骤
创建Django项目
django-admin startproject name
创建子应用
python manager.py startapp name
创建工程
在使用Flask框架时,项目工程目录的组织与创建是需要我们自己手动创建完成的。
在django中,项目工程目录可以借助django提供的命令帮助我们创建。
创建
创建工程的命令为:
例如:想要在桌面的code目录中创建一个名为bookmanager的项目工程,可执行如下命令:
执行后,会多出一个新目录名为bookmanager,此即为新创建的工程目录。
工程目录说明
查看创建的工程目录,结构如下

与项目同名的目录,此处为bookmanager。settings.py是项目的整体配置文件。urls.py是项目的URL配置文件。wsgi.py是项目与WSGI兼容的Web服务器入口。manage.py是项目管理文件,通过它管理项目。
运行开发服务器
在开发阶段,为了能够快速预览到开发的效果,django提供了一个纯python编写的轻量级web服务器,仅在开发阶段使用。
运行服务器命令如下:
可以不写IP和端口,默认IP是127.0.0.1,默认端口为8000。
启动后可见如下信息:

在浏览器中输入网址“127.0.0.1:8099”便可看到效果。

django默认工作在调式Debug模式下,如果增加、修改、删除文件,服务器会自动重启。按ctrl+c停止服务器。
创建子应用
在Web应用中,通常有一些业务功能模块是在不同的项目中都可以复用的,故在开发中通常将工程项目拆分为不同的子功能模块,各功能模块间可以保持相对的独立,在其他工程项目中需要用到某个特定功能模块时,可以将该模块代码整体复制过去,达到复用。
在Flask框架中也有类似子功能应用模块的概念,即蓝图Blueprint。
Django的视图编写是放在子应用中的。
创建
在django中,创建子应用模块目录仍然可以通过命令来操作,即:
manage.py为上述创建工程时自动生成的管理文件。
例如,在刚才创建的bookmanager工程中,想要创建一个用户book子应用模块,可执行:
执行后,可以看到工程目录中多出了一个名为book的子目录。
wps office 的官方的下载的网站是什么
子应用目录说明
查看此时的工程目录,结构如下:

admin.py文件跟网站的后台管理站点配置相关。apps.py文件用于配置当前子应用的相关信息。migrations目录用于存放数据库迁移历史文件WPS office的电脑版的下载地址。models.py文件用户保存数据库模型类。tests.py文件用于开发测试用例,编写单元测试。views.py文件用于编写Web应用视图。
注册安装子应用
创建出来的子应用目录文件虽然被放到了工程项目目录中,但是django工程并不能立即直接使用该子应用,需要注册安装后才能使用。
在工程配置文件settings.py中,INSTALLED_APPS项保存了工程中已经注册安装的子应用,初始工程中的INSTALLED_APPS如下:

注册安装一个子应用的方法,即是将子应用的配置信息文件apps.py中的Config类添加到INSTALLED_APPS列表中。
例如,将刚创建的book子应用添加到工程中,可在INSTALLED_APPS列表中添加'book.apps.BookConfig'。

当前项目的开发, 都是数据驱动的。
以下为书籍信息管理的数据关系:书籍和人物是 :一对多关系

要先分析出项目中所需要的数据, 然后设计数据库表.
书籍信息表
字段名字段类型字段说明idAutoField主键nameCharField书名
idname1西游记2三国演义
人物信息表
字段名字段类型字段说明idAutoField主键nameCharField人名genderBooleanField性别bookForeignKey外键
idnamegenderbook1孙悟空False12白骨精True13曹操False24貂蝉True2
使用Django进行数据库开发的提示 :
设计模式中的, 专门负责和数据库交互.对应由于中内嵌了, 所以不需要直接面向数据库编程.而是定义模型类, 通过完成数据库表的.就是把数据库表的行与相应的对象建立关联, 互相转换.使得数据库的操作面向对象.
使用Django进行数据库开发的步骤 :
定义模型类模型迁移操作数据库
1. 定义模型类
根据书籍表结构设计模型类:
模型类:BookInfo书籍名称字段:name根据人物表结构设计模型类:
模型类:PeopleInfo人物姓名字段:name人物性别字段:gender外键约束:book
外键要指定所属的模型类说明 :
书籍-人物的关系为一对多. 一本书中可以有多个英雄.不需要定义主键字段, 在生成表时会自动添加, 并且值为自增长.
根据数据库表的设计
在中定义模型类,继承自
模型迁移 (建表)
迁移由两步完成 :
生成迁移文件:根据模型类生成创建表的语句
执行迁移:根据第一步生成的语句在数据库中创建表
迁移前

迁移后
 此处存在的问题
此处存在的问题
运行迁移命令报错

原因:
在django2.0后,定义外键和一对一关系的时候需要加on_delete选项,此参数为了避免两个表里的数据不一致问题,不然会报错:
TypeError: __init__() missing 1 required positional argument: 'on_delete'
举例:
应该为
参数说明:
on_delete有CASCADE、PROTECT、SET_NULL、SET_DEFAULT、SET()五个可选择的值
CASCADE:此值设置,是级联删除。PROTECT:此值设置,是会报完整性错误。SET_NULL:此值设置,会把外键设置为null,前提是允许为null。SET_DEFAULT:此值设置,会把设置为外键的默认值。SET():此值设置,会调用外面的值,可以是一个函数。
一般情况下使用CASCADE就可以了。
站点: 分为和两部分内容发布的部分由网站的管理员负责查看、添加、修改、删除数据能够根据定义的模型类自动地生成管理模块使用的管理模块, 需要按照如下步骤操作 :
1.管理界面本地化2.创建管理员3.注册模型类4.发布内容到数据库
管理界面本地化
本地化是将显示的语言、时间等使用本地的习惯,这里的本地化就是进行中国化.中国大陆地区使用, 时区使用, 注意这里不使用北京时区.
本地化前

本地化后

创建管理员
创建管理员的命令 :
按提示输入用户名、邮箱、密码

重置密码
登陆站点 :
需要服务器是启动状态

登陆站点成功
站点界面中没有书籍和人物管理入口,因为没有注册模型类

注册模型类
在的文件中注册模型类
需要导入模型模块 :

注册模型后

注册模型成功后, 就可以在站点管理界面方便快速的管理数据.
发布内容到数据库

然后就报错了

原来不会去数据库生成数据表,还要自己手动去创建

站点管理页面做好了, 接下来就要做的页面了.对于的设计框架.
用户在URL中请求的是视图.视图接收请求后进行处理.并将处理的结果返回给请求者.使用视图时需要进行两步操作
1.定义视图2.配置URLconf
定义视图
视图就是一个函数,被定义在的中.视图的第一个参数是类型的对象,包含了所有.视图必须返回,包含返回给请求者的.
需要导入模块 :
定义视图函数 : 响应字符串给客户端

配置URLconf
查找视图的过程 :
1.请求者在浏览器地址栏中输入URL, 请求到网站.2.网站获取URL信息.3.然后与编写好的URLconf逐条匹配.4.如果匹配成功则调用对应的视图.
5.如果所有的URLconf都没有匹配成功.则返回404错误.

入口

需要两步完成配置
1.在中定义2.在中定义
在中定义
django.urls 中的 path() 和 django.conf.urls 中的 url() 都是 Django 中用于 URL 路由的函数,它们的作用是定义 URL 和视图函数之间的映射关系,即当用户访问某个 URL 时,Django 如何将请求发送给对应的视图函数来处理。
两者的区别如下:
path() 函数是 Django 2.0 版本引入的新函数,它更加直观和易用,支持使用 str 类型的路由,可以通过等转换器来定义动态参数,而且不再需要使用正则表达式来匹配 URL,大大简化了 URL 配置的过程。例如:
需要注意的是,在 Django 3.1 版本以后,url() 函数已经被标记为过时,建议使用 path() 函数来进行 URL 配置。因此,如果使用较新版本的 Django,应该尽量使用 path() 函数来定义 URL 路由。
看下path()函数用法:
在 Django 中,path() 函数是用来定义 URL 路由的。它的语法如下:
其中:
route:是一个字符串,用来匹配 URL,可以包含变量,例如:'articles/<int:pk>/'。当有请求发生时,Django 会尝试将该字符串与请求的 URL 进行匹配,如果匹配成功,就会调用对应的 view 函数处理该请求。view:是一个视图函数或者一个类视图,用来处理匹配成功的请求,并返回一个响应对象。kwargs:是一个可选的字典,包含额外的关键字参数,传递给视图函数。name:是一个可选的字符串,用来给 URL 路由起一个名称,方便在模板中使用。
path() 函数支持的 URL 模式有以下几种:
静态 URL 模式,例如 ‘articles/’。带参数的 URL 模式,例如 'articles/<int:pk>/',其中 <int:pk> 表示一个整数类型的参数。带参数的 URL 模式,例如 'articles/<slug:slug>/',其中 <slug:slug> 表示一个字符串类型的参数,但是只能包含 ASCII 字符、数字、下划线或连字符。带可选参数的 URL 模式,例如 'articles/<int:pk>/<str:slug>/',其中 <str:slug> 表示一个可选的字符串类型的参数。匹配任意字符的 URL 模式,例如 'articles/<path:path>/',其中 <path:path> 可以匹配包含 / 符号的任意字符串。
在定义 URL 路由时,可以使用多个 path() 函数来定义不同的路由,并将它们作为列表传递给 urlpatterns 变量。例如:
上面的代码中,定义了两个 URL 路由,分别对应 /articles/ 和 /articles/int:pk/ 两个 URL。其中,views.article_list 和 views.article_detail 分别是处理请求的视图函数。
Django2. 0中可以使用 re_path() 方法来兼容 1.x 版本中的 url() 方法,一些正则表达式的规则也可以通过 re_path() 来实现。
参考资料:django2笔记:路由path语法 | 程序员Barnes的博客
我们采用的是django2.0所以我们采用path语法

在中定义
提示:一条包括URL规则、视图两部分
URL规则使用正则表达式定义.
视图就是在中定义的视图函数.
from book import views

url匹配过程

测试:请求访问

总结
视图处理过程如下图:

使用视图时需要进行两步操作,两步操作不分先后
配置在中定义视图
思考 : 网站如何向客户端返回一个漂亮的页面呢?
提示 :
漂亮的页面需要、、.可以把这一堆字段串全都写到视图中, 作为的参数,响应给客户端.
问题 :
视图部分代码臃肿, 耦合度高.这样定义的字符串是不会出任何效果和错误的.效果无法及时查看.有错也不容易及时发现.
设想 :
是否可以有一个专门定义前端页面的地方, 效果可以及时展示,错误可以及时发现,并且可以降低模块间耦合度!
解决问题 :模板
设计模式中的,
在中, 将前端的内容定义在模板中, 然后再把模板交给视图调用, 各种漂亮、炫酷的效果就出现了.
模板使用步骤
创建模板2.设置模板查找路径3.模板接收视图传入的数据4.模板处理数据
创建模板
在同级目录下创建模板文件夹. 文件夹名称固定写法.在文件夹下, 创建同名文件夹. 例,
在同名文件夹下创建文件. 例 :

设置模板查找路径

模板接收视图传入的数据
视图模板加载

模板处理数据

查看模板处理数据成果

展示书籍列表
需求

实现步骤
1.创建视图2.创建模板3.配置URLconf
创建视图
查询数据库数据构造上下文
传递上下文到模板
创建模板
读取上下文数据构造网页html文档 : 书籍信息以列表样式展示

配置URLconf
进入中的文件


效果

setting配置文件
BASE_DIR
代表的是settings.py文件,那么的结果将会是settings.py文件的绝对路径;然后parent取其父目录,两个parent就是向上两层父级目录 ,也就是django-admin创建项目之后的路径。

DEBUG
调试模式,创建工程后初始值为True,即默认工作在调试模式下。
作用:
修改代码文件,程序自动重启
Django程序出现异常时,向前端显示详细的错误追踪信息,例如

而非调试模式下,仅返回Server Error (500)
注意:部署线上运行的Django不要运行在调式模式下,记得修改DEBUG=False和ALLOW_HOSTS。
本地语言与时区
Django支持本地化处理,即显示语言与时区支持本地化。
本地化是将显示的语言、时间等使用本地的习惯,这里的本地化就是进行中国化,中国大陆地区使用简体中文,时区使用亚洲/上海时区,注意这里不使用北京时区表示。
初始化的工程默认语言和时区为英语和UTC标准时区
将语言和时区修改为中国大陆信息
静态文件
项目中的CSS、图片、js都是静态文件。一般会将静态文件放到一个单独的目录中,以方便管理。在html页面中调用时,也需要指定静态文件的路径,Django中提供了一种解析的方式配置静态文件路径。静态文件可以放在项目根目录下,也可以放在应用的目录下,由于有些静态文件在项目中是通用的,所以推荐放在项目的根目录下,方便管理。
为了提供静态文件,需要配置两个参数:
STATICFILES_DIRS存放查找静态文件的目录STATIC_URL访问静态文件的URL前缀
示例
1) 在项目根目录下创建static目录来保存静态文件。
2) 在bookmanager/settings.py中修改静态文件的两个参数为
3)此时在static添加的任何静态文件都可以使用网址/static/文件在static中的路径来访问了。
例如,我们向static目录中添加一个index.html文件,在浏览器中就可以使用127.0.0.1:8099/static/index.html来访问。
或者我们在static目录中添加了一个子目录和文件book/detail.html,在浏览器中就可以使用127.0.0.1:8099/static/book/detail.html来访问。


APP应用配置
在每个应用目录中都包含了apps.py文件,用于保存该应用的相关信息。
在创建应用时,Django会向apps.py文件中写入一个该应用的配置类,如
我们将此类添加到工程settings.py中的INSTALLED_APPS列表中,表明注册安装具备此配置属性的应用。
AppConfig.name属性表示这个配置类是加载到哪个应用的,每个配置类必须包含此属性,默认自动生成。
AppConfig.verbose_name属性用于设置该应用的直观可读的名字,此名字在Django提供的Admin管理站点中会显示,如

重点
模型配置
数据的增删改
增: 和
删: 和
改: 和
数据的查询
基础查询
F对象和Q对象
关联查询
查询集QuerySet

Django默认初始配置使用sqlite数据库,我们现在使用MySQL数据来进行改造,下面是使用sqlite数据库的配置文件。
使用MySQL数据库首先需要安装驱动程序
在Django的工程同名子目录的__init__.py文件中添加如下语句
作用是让Django的ORM能以mysqldb的方式来调用PyMySQL。

修改DATABASES配置信息

在MySQL中创建数据库
模型类被定义在"应用/models.py"文件中。模型类必须继承自Model类,位于包django.db.models中。
定义
在models.py 文件中定义模型类。
数据库表名
数据库表名
模型类如果未指明表名,Django默认以小写app应用名_小写模型类名为数据库表名。
可通过db_table指明数据库表名。
关于主键
django会为表创建自动增长的主键列,每个模型只能有一个主键列,如果使用选项设置某属性为主键列后django不会再创建自动增长的主键列。
默认创建的主键列属性为id,可以使用pk代替,pk全拼为primary key。
属性命名限制
不能是python的保留关键字。不允许使用连续的下划线,这是由django的查询方式决定的。
定义属性时需要指定字段类型,通过字段类型的参数指定选项,语法如下:
字段类型
类型说明AutoField自动增长的IntegerField,通常不用指定,不指定时Django会自动创建属性名为id的自动增长属性BooleanField布尔字段,值为True或FalseNullBooleanField支持Null、True、False三种值CharField字符串,参数max_length表示最大字符个数TextField大文本字段,一般超过4000个字符时使用IntegerField整数DecimalField十进制浮点数, 参数max_digits表示总位数, 参数decimal_places表示小数位数FloatField浮点数DateField日期, 参数auto_now表示每次保存对象时,自动设置该字段为当前时间,用于"最后一次修改"的时间戳,它总是使用当前日期,默认为False; 参数auto_now_add表示当对象第一次被创建时自动设置当前时间,用于创建的时间戳,它总是使用当前日期,默认为False; 参数auto_now_add和auto_now是相互排斥的,组合将会发生错误TimeField时间,参数同DateFieldDateTimeField日期时间,参数同DateFieldFileField上传文件字段ImageField继承于FileField,对上传的内容进行校验,确保是有效的图片
选项
选项说明null如果为True,表示允许为空,默认值是Falseblank如果为True,则该字段允许为空白,默认值是Falsedb_column字段的名称,如果未指定,则使用属性的名称db_index若值为True, 则在表中会为此字段创建索引,默认值是Falsedefault默认primary_key若为True,则该字段会成为模型的主键字段,默认值是False,一般作为AutoField的选项使用unique如果为True, 这个字段在表中必须有唯一值,默认值是False
null是数据库范畴的概念,blank是表单验证范畴的
外键
在设置外键时,需要通过on_delete选项指明主表删除数据时,对于外键引用表数据如何处理,在django.db.models中包含了可选常量:
CASCADE级联,删除主表数据时连通一起删除外键表中数据
PROTECT保护,通过抛出ProtectedError异常,来阻止删除主表中被外键应用的数据
SET_NULL设置为NULL,仅在该字段null=True允许为null时可用
SET_DEFAULT设置为默认值,仅在该字段设置了默认值时可用
SET()设置为特定值或者调用特定方法
DO_NOTHING不做任何操作,如果数据库前置指明级联性,此选项会抛出IntegrityError异常
迁移
迁移是 Django 将你对模型的修改(例如增加一个字段,删除一个模型)应用至数据库架构中的方式。它们被设计的尽可能自动化,但你仍需要知道何时构建和运行迁移,你还需要了解一些常见问题。
以下是几个常用的与迁移交互的命令,即 Django 处理数据库架构的方式:
migrate,负责应用和撤销迁移。makemigrations,基于模型的修改创建迁移。sqlmigrate,展示迁移使用的 SQL 语句。showmigrations,列出项目的迁移和迁移的状态。
你应该将迁移看作是数据库架构的版本控制系统。 负责将模型修改打包进独立的迁移文件中——类似提交修改,而 负责将其应用至数据库。
每个应用的迁移文件位于该应用的 "migrations" 目录中,他们被设计成应用代码的一部分,与应用代码一起被提交,被发布。你只需在开发机上构建一次,就可以在同事的电脑或测试机上运行同样的迁移而保证结果一致。最后在生产环境运行同样的迁移。
简单来说就是将模型类同步到数据库中。
生成迁移文件

同步到数据库中

添加测试数据
Django的manage工具提供了shell命令,帮助我们配置好当前工程的运行环境(如连接好数据库等),以便可以直接在终端中执行测试python语句。
通过如下命令进入shell

导入两个模型类,以便后续使用
增加
增加数据有两种方法。
save
通过创建模型类对象,执行对象的save()方法保存到数据库中。


create
通过模型类.objects.create()保存。


修改
修改更新有两种方法
save
修改模型类对象的属性,然后执行save()方法


update
使用模型类.objects.filter().update(),会返回受影响的行数
删除
删除有两种方法
模型类对象delete
模型类.objects.filter().delete()


基础条件查询
基本查询
get查询单一结果,如果不存在会抛出模型类.DoesNotExist异常。(pk指的就是主键id)
all查询多个结果。
count查询结果数量。


过滤查询
实现SQL中的where功能,包括
filter过滤出多个结果exclude排除掉符合条件剩下的结果get过滤单一结果
对于过滤条件的使用,上述三个方法相同,故仅以filter进行讲解。
过滤条件的表达语法如下:
相等
exact:表示判等。
例:查询编号为1的图书。

模糊查询
contains:是否包含。
说明:如果要包含%无需转义,直接写即可。
例:查询书名包含'传'的图书。

startswith、endswith:以指定值开头或结尾。
例:查询书名以'部'结尾的图书

以上运算符都区分大小写,在这些运算符前加上i表示不区分大小写,如iexact、icontains、istartswith、iendswith.
空查询
isnull:是否为null。
例:查询书名为空的图书。

范围查询
in:是否包含在范围内。
例:查询编号为1或3或5的图书

比较查询
gt大于 (greater then)gte大于等于 (greater then equal)lt小于 (less then)lte小于等于 (less then equal)
例:查询编号大于3的图书

不等于的运算符,使用exclude()过滤器。
例:查询编号不等于3的图书

日期查询
year、month、day、week_day、hour、minute、second:对日期时间类型的属性进行运算。
例:查询1980年发表的图书。

例:查询1990年1月1日后发表的图书。
wps的的官网最新下载的地址是什么
F和Q对象
F对象
之前的查询都是对象的属性与常量值比较,两个属性怎么比较呢? 答:使用F对象,被定义在django.db.models中。
语法如下:
例:查询阅读量大于等于评论量的图书。

可以在F对象上使用算数运算。
例:查询阅读量大于2倍评论量的图书。

Q对象
多个过滤器逐个调用表示逻辑与关系,同sql语句中where部分的and关键字。
例:查询阅读量大于20,并且编号小于3的图书。

如果需要实现逻辑或or的查询,需要使用Q()对象结合|运算符,Q对象被义在django.db.models中。
语法如下:
例:查询阅读量大于20的图书,改写为Q对象如下。
Q对象可以使用&、|连接,&表示逻辑与,|表示逻辑或。
例:查询阅读量大于20,或编号小于3的图书,只能使用Q对象实现

Q对象前可以使用~操作符,表示非not。
例:查询编号不等于3的图书。

聚合函数和排序函数
聚合函数
使用aggregate()过滤器调用聚合函数。聚合函数包括:Avg平均,Count数量,Max最大,Min最小,Sum求和,被定义在django.db.models中。
例:查询图书的总阅读量。

注意aggregate的返回值是一个字典类型,格式如下:
使用count时一般不使用aggregate()过滤器。
例:查询图书总数。
注意count函数的返回值是一个数字。
排序
使用order_by对结果进行排序

关联查询
由一到多的访问语法:
一对应的模型类对象.多对应的模型类名小写_set 例:

由多到一的访问语法:
多对应的模型类对象.多对应的模型类中的关系类属性名 例:

访问一对应的模型类关联对象的id语法:
多对应的模型类对象.关联类属性_id
例:

关联过滤查询
由多模型类条件查询一模型类数据:
语法如下:
注意:如果没有"__运算符"部分,表示等于。
例:
查询图书,要求图书人物为"郭靖"

查询图书,要求图书中人物的描述包含"八"

由一模型类条件查询多模型类数据:
语法如下:
注意:如果没有"__运算符"部分,表示等于。
例:
查询书名为“天龙八部”的所有人物。

查询图书阅读量大于30的所有人物

查询集QerySet
概念
Django的ORM中存在查询集的概念。
查询集,也称查询结果集、QuerySet,表示从数据库中获取的对象集合。
当调用如下过滤器方法时,Django会返回查询集(而不是简单的列表):
all():返回所有数据。filter():返回满足条件的数据。exclude():返回满足条件之外的数据。order_by():对结果进行排序。
对查询集可以再次调用过滤器进行过滤,如

也就意味着查询集可以含有零个、一个或多个过滤器。过滤器基于所给的参数限制查询的结果。
从SQL的角度讲,查询集与select语句等价,过滤器像where、limit、order by子句。
判断某一个查询集中是否有数据:
exists():判断查询集中是否有数据,如果有则返回True,没有则返回False。
两大特性
惰性执行
创建查询集不会访问数据库,直到调用数据时,才会访问数据库,调用数据的情况包括迭代、序列化、与if合用
例如,当执行如下语句时,并未进行数据库查询,只是创建了一个查询集books
继续执行遍历迭代操作后,才真正的进行了数据库的查询
缓存
使用同一个查询集,第一次使用时会发生数据库的查询,然后Django会把结果缓存下来,再次使用这个查询集时会使用缓存的数据,减少了数据库的查询次数。
情况一:如下是两个查询集,无法重用缓存,每次查询都会与数据库进行一次交互,增加了数据库的负载。

情况二:经过存储后,可以重用查询集,第二次使用缓存中的数据。

限制查询集
可以对查询集进行取下标或切片操作,等同于sql中的limit和offset子句。
注意:不支持负数索引。
对查询集进行切片后返回一个新的查询集,不会立即执行查询。
如果获取一个对象,直接使用[0],等同于[0:1].get(),但是如果没有数据,[0]引发IndexError异常,[0:1].get()如果没有数据引发DoesNotExist异常。
示例:获取第1、2项,运行查看。

分页
Pagination | Django documentation | Django (djangoproject.com)

视图介绍
视图就是中文件中的函数视图的第一个参数必须为,还可能包含下参数如
通过正则表达式组获取的位置参数通过正则表达式组获得的关键字参数视图必须返回一个或作为响应
子对象: 视图负责接受Web请求,进行逻辑处理,返回Web响应给请求者
响应内容可以是,,,…
视图处理过程如下图:

使用视图时需要进行两步操作,两步操作不分先后
配置在中定义视图
项目准备
创建项目+创建应用+安装应用+配置模板路径+本地化+mysql数据库+URLconf+视图
mysql数据库使用之前的book
URLconf
中:指定url配置
项目中:只要不是就匹配成功,包含到应用中的
应用中:匹配成功就调用中的函数,测试项目逻辑
视图:测试项目逻辑
在models.py 文件中定义模型类
生成迁移文件
同步到数据库中
添加测试数据

浏览者通过在浏览器的地址栏中输入网址请求网站对于Django开发的网站,由哪一个视图进行处理请求,是由url匹配找到的
配置URLconf
1.中
指定url配置
2.项目中
匹配成功后,包含到应用的
3.应用中
匹配成功后,调用对应的函数
路由命名是给你写的路由起一个名字,reverse反解析能给根据名字解析出对应的路由。
路由命名
在定义路由的时候,可以为路由命名,方便查找特定视图的具体路径信息。
1) 在使用include函数定义路由时,可以使用namespace参数定义路由的命名空间,如

命名空间表示,凡是book.urls中定义的路由,均属于namespace指明的book名下。
命名空间的作用:避免不同应用中的路由使用了相同的名字发生冲突,使用命名空间区别开。
2) 在定义普通路由时,可以使用name参数指明路由的名字,如

reverse反解析
使用reverse函数,可以根据路由名称,返回具体的路径,如:
对于未指明namespace的,reverse(路由name)对于指明namespace的,reverse(命名空间namespace:路由name)


PostMan 是一款功能强大的网页调试与发送网页 HTTP 请求的 Chrome 插件,可以直接去对我们写出来的路由和视图函数进行调试,作为后端程序员是必须要知道的一个工具。
Postman API Platform官网下载桌面版
回想一下,利用HTTP协议向服务器传参有几种途径?
提取URL的特定部分,如/weather/beijing/2018,可以在服务器端的路由中用正则表达式截取;查询字符串(query string),形如key1=value1&key2=value2;请求体(body)中发送的数据wps官网下载的入口在哪,比如表单数据、json、xml;在http报文的头(header)中。
URL路径参数
如果想从URL中获取值,需要在正则表达式中使用,获取值分为两种方式
位置参数
参数的位置不能错关键字参数
参数的位置可以变,跟关键字保持一致即可注意:两种参数的方式不要混合使用,在一个正则表达式中只能使用一种参数方式分别使用以上两种获取URL值的方式提取出
127.0.0.1:8099/booklist/testPath/1/2/
位置参数
应用中
视图中函数: 参数的位置不能错
如果将<num1>改为 <int:num1>,会进行类型约束,如果传入参数不为int型报错,相似的有:
int:接收整数
str:字符串
path:可以接收包含"/"的路径
slug:接收【数字、字母、下划线、中划线】四种字符





关键字参数
如果,使用path函数并不能满足你匹配URL的要求,那么可以使用re_path函数来使用正则表达式来匹配URL路径中的参数。需要注意在Django中,使用正则表达式来获取分组中的值的语法是,其中 name 是组名,pattern 是要匹配的模式。
应用中
其中部分表示为这个参数定义的名称为
可以是其它名称,起名要做到见名知意
视图中函数: 参数的位置可以变,跟关键字保持一致即可


 Django中的QueryDict对象
Django中的QueryDict对象
HttpRequest对象的属性GET、POST都是QueryDict类型的对象
与python字典不同,QueryDict类型的对象用来处理同一个键带有多个值的情况
方法get():根据键获取值
如果一个键同时拥有多个值将获取最后一个值
如果键不存在则返回None值,可以设置默认值进行后续处理
方法getlist():根据键获取值,值以列表返回,可以获取指定键的所有值
如果键不存在则返回空列表[],可以设置默认值进行后续处理
查询字符串Query String
获取请求路径中的查询字符串参数(形如?k1=v1&k2=v2),可以通过request.GET属性获取,返回QueryDict对象。


重要:查询字符串不区分请求方式,即假使客户端进行POST方式的请求,依然可以通过request.GET获取请求中的查询字符串数据。
请求体
请求体数据格式不固定,可以是表单类型字符串,可以是JSON字符串,可以是XML字符串,应区别对待。
可以发送请求体数据的请求方式有POST、PUT、PATCH、DELETE。
Django默认开启了CSRF防护,会对上述请求方式进行CSRF防护验证,在测试时可以关闭CSRF防护机制,方法为在settings.py文件中注释掉CSRF中间件,如:

表单类型 Form Data
前端发送的表单类型的请求体数据,可以通过request.POST属性获取,返回QueryDict对象。


因为浏览器不好发送post请求,所以我们用postman来测试
WPS office的官网最新的下载的入口的方法
1填入的路径http://127.0.0.1:8099/booklist/post/
2是填入的参数
3是点击发送
4是结果
非表单类型 Non-Form Data
非表单类型的请求体数据,Django无法自动解析,可以通过request.body属性获取最原始的请求体数据,自己按照请求体格式(JSON、XML等)进行解析。request.body返回bytes类型。
例如要获取请求体中的如下JSON数据
可以进行如下方法操作:



请求头
可以通过request.META属性获取请求头headers中的数据,request.META为字典类型。
常见的请求头如:
– The length of the request body (as a string).– The MIME type of the request body.– Acceptable content types for the response.– Acceptable encodings for the response.– Acceptable languages for the response.– The HTTP Host header sent by the client.– The referring page, if any.– The client’s user-agent string.– The query string, as a single (unparsed) string.– The IP address of the client.– The hostname of the client.– The user authenticated by the Web server, if any.– A string such asor.– The hostname of the server.– The port of the server (as a string).
具体使用如:




其他常用HttpRequest对象属性
method:一个字符串,表示请求使用的HTTP方法,常用值包括:'GET'、'POST'wps 的官网下载网址(wps office下载官网免费下载)。user:请求的用户对象。path:一个字符串,表示请求的页面的完整路径,不包含域名和参数部分。
encoding:一个字符串,表示提交的数据的编码方式。
如果为None则表示使用浏览器的默认设置,一般为utf-8。这个属性是可写的,可以通过修改它来修改访问表单数据使用的编码,接下来对属性的任何访问将使用新的encoding值。
FILES:一个类似于字典的对象,包含所有的上传文件。

视图在接收请求并处理后,必须返回HttpResponse对象或子对象。HttpRequest对象由Django创建,HttpResponse对象由开发人员创建。
HttpResponse
可以使用django.http.HttpResponse来构造响应对象。
也可通过HttpResponse对象属性来设置响应体、响应体数据类型、状态码:
content:表示返回的内容。status_code:返回的HTTP响应状态码。
响应头可以直接将HttpResponse对象当做字典进行响应头键值对的设置:
示例:



HttpResponse子类
Django提供了一系列HttpResponse的子类,可以快速设置状态码
HttpResponseRedirect 301HttpResponsePermanentRedirect 302HttpResponseNotModified 304HttpResponseBadRequest 400HttpResponseNotFound 404HttpResponseForbidden 403HttpResponseNotAllowed 405HttpResponseGone 410HttpResponseServerError 500


JsonResponse
若要返回json数据,可以使用JsonResponse来构造响应对象,作用:
帮助我们将数据转换为json字符串设置响应头Content-Type为application/json

redirect重定向

浏览器请求服务器是无状态的。无状态:指一次用户请求时,浏览器、服务器无法知道之前这个用户做过什么,每次请求都是一次新的请求。无状态原因:浏览器与服务器是使用Socket套接字进行通信的,服务器将请求结果返回给浏览器之后,会关闭当前的Socket连接,而且服务器也会在处理页面完毕之后销毁页面对象。有时需要保持下来用户浏览的状态,比如用户是否登录过,浏览过哪些商品等实现状态保持主要有两种方式:
在客户端存储信息使用在服务器端存储信息使用
Cookie
Cookie,有时也用其复数形式Cookies,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)。Cookie最早是网景公司的前雇员Lou Montulli在1993年3月的发明。Cookie是由服务器端生成,发送给User-Agent(一般是浏览器),浏览器会将Cookie的key/value保存到某个目录下的文本文件内,下次请求同一网站时就发送该Cookie给服务器(前提是浏览器设置为启用cookie)。Cookie名称和值可以由服务器端开发自己定义,这样服务器可以知道该用户是否是合法用户以及是否需要重新登录等。服务器可以利用Cookies包含信息的任意性来筛选并经常性维护这些信息,以判断在HTTP传输中的状态。Cookies最典型记住用户名。
Cookie是存储在浏览器中的一段纯文本信息,建议不要存储敏感信息如密码,因为电脑上的浏览器可能被其它人使用。
cookie的工作原理:
第一次请求过程:
我们的浏览器第一次请求服务器的时候,不会携带任何cookie信息
服务器接收到请求之后,发现,请求中没有任何cookie信息
服务器设置一个cookie,这个cookie设置在应中
我们的浏览器接收到这个响应之后,发现响应中有cookie信息,浏览器会将cookie信息保存起来
第二次及其之后的过程
当我们的浏览器第二次及其之后的请求都会携带cookie信息
我们的服务器接收到请求之后,会发现请求中携带的cookie信息,这样的话就认识是谁的请求了
不设置cookie时浏览器控制台cookie情况




后端不设置cookie,也会返回一个默认的cookie
然后我们看看手动设置cookie的情况

 会返回默认和自己设置的,访问服务器的时候会带上。
会返回默认和自己设置的,访问服务器的时候会带上。

Cookie的特点
Cookie以键值对的格式进行信息的存储。Cookie基于域名安全,不同域名的Cookie是不能互相访问的,如访问itcast.cn时向浏览器中写了Cookie信息,使用同一浏览器访问baidu.com时,无法访问到itcast.cn写的Cookie信息。当浏览器请求某网站时,会将浏览器存储的跟网站相关的所有Cookie信息提交给网站服务器。
设置Cookie
可以通过HttpResponse对象中的set_cookie方法来设置cookie。
max_age单位为秒,默认为None 。如果是临时cookie,可将max_age设置为None。
示例:
读取Cookie
可以通过HttpResponse对象的COOKIES属性来读取本次请求携带的cookie值。request.COOKIES为字典类型。
删除Cookie
可以通过HttpResponse对象中的delete_cookie方法来删除。
Session
保存在服务器的数据叫做 session,session需要依赖于cookie,如果浏览器禁用了cookie,则session不能实现。
session流程:
第一次请求:
我们第一次请求的时候可以携带一些信息(用户名/密码) cookie中没有任何信息
当我们的服务器接收到这个请求之后,进行用户名和密码的验证,验证没有问题可以设置session信息
在设置session信息的同时(session信息保存在服务器端).服务器会在响应头中设置一个 sessionid 的cookie信息(由服务器自己设置的,不是我们设置的)
客户端(浏览器)在接收到响应之后,会将cookie信息保存起来(保存 sessionid的信息)
第二次及其之后的请求:
第二次及其之后的请求都会携带 session id信息
当服务器接收到这个请求之后,会获取到sessionid信息,然后进行验证, 验证成功,则可以获取 session信息(session信息保存在服务器端)

启用Session
Django项目默认启用Session。
可以在settings.py文件中查看,如图所示

如需禁用session,将上图中的session中间件注释掉即可。
存储方式
在settings.py文件中,可以设置session数据的存储方式,可以保存在数据库、本地缓存等。
数据库
存储在数据库中,如下设置可以写,也可以不写,这是默认存储方式。
如果存储在数据库中,需要在项INSTALLED_APPS中安装Session应用。

数据库中的表如图所示


由表结构可知,操作Session包括三个数据:键,值,过期时间。
本地缓存
存储在本机内存中,如果丢失则不能找回,比数据库的方式读写更快。
混合存储
存储在本机内存中,如果丢失则不能找回,比数据库的方式读写更快。
Redis
在redis中保存session,需要引入第三方扩展,我们可以使用django-redis来解决。
1) 安装扩展
2)配置
在settings.py文件中做如下设置
Session操作
通过HttpRequest对象的session属性进行会话的读写操作。
1) 以键值对的格式写session。
2)根据键读取值。
3)清除所有session,在存储中删除值部分。
4)清除session数据,在存储中删除session的整条数据。
5)删除session中的指定键及值,在存储中只删除某个键及对应的值。
6)设置session的有效期
如果value是一个整数,session将在value秒没有活动后过期。如果value为0,那么用户session的Cookie将在用户的浏览器关闭时过期。如果value为None,那么session有效期将采用系统默认值, 默认为两周,可以通过在settings.py中设置SESSION_COOKIE_AGE来设置全局默认值。
案列:使用数据库模式


不设置session,则控制台没有sessionId;


设置session,则控制台有sessionId; 
访问获取session
类视图
思考:一个视图,是否可以处理两种逻辑?比如get和post请求逻辑。
如何在一个视图中处理get和post请求

注册视图处理get和post请求
以函数的方式定义的视图称为函数视图,函数视图便于理解。但是遇到一个视图对应的路径提供了多种不同HTTP请求方式的支持时,便需要在一个函数中编写不同的业务逻辑,代码可读性与复用性都不佳。
类视图使用
在Django中也可以使用类来定义一个视图,称为类视图。
使用类视图可以将视图对应的不同请求方式以类中的不同方法来区别定义。如下所示
类视图的好处:
代码可读性好类视图相对于函数视图有更高的复用性 , 如果其他地方需要用到某个类视图的某个特定逻辑,直接继承该类视图即可
类视图原理
类视图的多继承重写dispatch
使用面向对象多继承的特性。

中间件
Django中的中间件是一个轻量级、底层的插件系统,可以介入Django的请求和响应处理过程,修改Django的输入或输出。中间件的设计为开发者提供了一种无侵入式的开发方式,增强了Django框架的健壮性。
我们可以使用中间件,在Django处理视图的不同阶段对输入或输出进行干预。
中间件的定义方法
定义一个中间件工厂函数,然后返回一个可以被调用的中间件。
中间件工厂函数需要接收一个可以调用的get_response对象。
返回的中间件也是一个可以被调用的对象,并且像视图一样需要接收一个request对象参数,返回一个response对象。
例如,在book应用中新建一个middleware.py文件,
定义好中间件后,需要在settings.py 文件中添加注册中间件
定义一个视图进行测试

注意:Django运行在调试模式下,中间件init部分有可能被调用两次。
多个中间件的执行顺序
在请求视图被处理前,中间件由上至下依次执行在请求视图被处理后,中间件由下至上依次执行

示例:
定义两个中间件
注册添加两个中间件
执行结果

配置:
在工程中创建模板目录templates。
在settings.py配置文件中修改TEMPLATES配置项的DIRS值:
定义模板
在templates目录中新建一个模板文件,如index.html
模板渲染
调用模板分为两步骤:
找到模板 loader.get_template(模板文件在模板目录中的相对路径) -> 返回模板对象
渲染模板 模板对象.render(context=None, request=None) -> 返回渲染后的html文本字符串 context 为模板变量字典,默认值为None request 为请求对象,默认值为None
例如,定义一个视图
Django提供了一个函数render可以简写上述代码。
render(request对象, 模板文件路径, 模板数据字典)
模板语法
模板变量
变量名必须由字母、数字、下划线(不能以下划线开头)和点组成。
语法如下:
{{变量}}
模板变量可以使python的内建类型,也可以是对象。
模板语句
for循环:

if条件:

比较运算符如下:
布尔运算符如下:
注意:运算符左右两侧不能紧挨变量或常量,必须有空格。

注释
单行注释语法如下:
{#…..#}
多行注释使用comment标签,语法如下:
{% coment %}
………
{% endcomment %}
过滤器
语法如下:
使用管道符号|来应用过滤器,用于进行计算、转换操作,可以使用在变量、标签中。如果过滤器需要参数,则使用冒号:传递参数。
列举几个如下:
safe,禁用转义,告诉模板这个变量是安全的,可以解释执行
length,长度,返回字符串包含字符的个数,或列表、元组、字典的元素个数。
default,默认值,如果变量不存在时则返回默认值。
date,日期,用于对日期类型的值进行字符串格式化,常用的格式化字符如下:
Y表示年,格式为4位,y表示两位的年。m表示月,格式为01,02,12等。d表示日, 格式为01,02等。j表示日,格式为1,2等。H表示时,24进制,h表示12进制的时。i表示分,为0-59。s表示秒,为0-59。
模板继承
模板继承和类的继承含义是一样的,主要是为了提高代码重用,减轻开发人员的工作量。
父模板
如果发现在多个模板中某些内容相同,那就应该把这段内容定义到父模板中。
标签block:用于在父模板中预留区域,留给子模板填充差异性的内容,名字不能相同。 为了更好的可读性,建议给endblock标签写上名字,这个名字与对应的block名字相同。父模板中也可以使用上下文中传递过来的数据。
子模板
标签extends:继承,写在子模板文件的第一行。

子模版不用填充父模版中的所有预留区域,如果子模版没有填充,则使用父模版定义的默认值。
{% extends "父模板路径"%}
填充父模板中指定名称的预留区域。
jinja2介绍
Jinja2:是 Python 下一个被广泛应用的模板引擎,是由Python实现的模板语言,他的设计思想来源于 Django 的模板引擎,并扩展了其语法和一系列强大的功能,尤其是Flask框架内置的模板语言
由于django默认模板引擎功能不齐全,速度慢,所以我们也可以在Django中使用jinja2, jinja2宣称比django默认模板引擎快10-20倍。
Django主流的第三方APP基本上也都同时支持Django默认模板及jinja2,所以要用jinja2也不会有多少障碍。
安装jinja2模块
Django配置jinja2
Django配置jinja2

在项目文件中创建 jinja2_env.py 文件
在settings.py文件
遇到问题:

ERRORS:
?: (admin.E403) A 'django.template.backends.django.DjangoTemplates' instance must be configured in TEMPLATES in order to use the admin application.
根据报错提示,应该是 django 自带的 admin 模块需要使用 django 默认模板。
所以需要保留他自身的默认配置:

如果不想使用他自身的配置给出两种方案:
第一种去除掉admin 模块:
修改好上述三处代码之后,就可以正常使用了。
第二种方法直接建两个模板空间
jinja2模板的使用绝大多数和Django自带模板一样,不一样有:
jinja2自定义过滤器
在jinja2_env.py文件中自定义过滤器
全拼为,译为跨站请求伪造。指攻击者盗用了你的身份,以你的名义发送恶意请求。
包括:以你名义发送邮件,发消息,盗取你的账号,甚至于购买商品,WPS office的电脑版的下载网站怎么找转账……造成的问题:个人隐私泄露以及财产安全。
CSRF攻击示意图
客户端访问服务器时没有同服务器做安全验证
防止 CSRF 攻击
步骤
在客户端向后端请求界面数据的时候,后端会往响应中的 cookie 中设置 csrf_token 的值在 Form 表单中添加一个隐藏的的字段,值也是 csrf_token在用户点击提交的时候,会带上这两个值向后台发起请求后端接受到请求,以会以下几件事件:
从 cookie中取出 csrf_token从 表单数据中取出来隐藏的 csrf_token 的值进行对比如果比较之后两值一样,那么代表是正常的请求,如果没取到或者比较不一样,代表不是正常的请求,不执行下一步操作
代码演示
未进行 csrf 校验的 WebA
后端代码实现
前端登录页面代码
前端转账页面代码
运行测试,如果在未登录的情况下,不能直接进入转账页面,测试转账是成功的
攻击网站B的代码
后端代码实现
前端代码实现
运行测试,在用户登录网站A的情况下,点击网站B的按钮,可以实现伪造访问
在网站A中实现 csrf_token 校验的流程
导入生成 csrf_token 的函数
在渲染转账页面的,做以下几件事情:
生成 csrf_token 的值在返回转账页面的响应里面设置 csrf_token 到 cookie 中将 csrf_token 保存到表单的隐藏字段中
在转账模板表单中添加 csrf_token 隐藏字段
运行测试,进入到转账页面之后,查看 cookie 和 html 源代码

在执行转账逻辑之前进行 csrf_token 的校验
运行测试,用户直接在网站 A 操作没有问题,再去网站B进行操作,发现转账不成功,因为网站 B 获取不到表单中的 csrf_token 的隐藏字段,而且浏览器有同源策略,网站B是获取不到网站A的 cookie 的,所以就解决了跨站请求伪造的问题
Django默认是开启CSRF的

模板中设置 CSRF 令牌














 wps office的免费版的下载地方怎么找
wps office的免费版的下载地方怎么找